C언어 포인터 산술 (Pointer Arithmetic)
선수학습(1개)
요약
C언어 포인터 산술의 핵심 개념을 알아봅니다. 포인터에 정수를 더하거나 빼는 연산, 문자열 포인터 산술, 배열과 포인터의 관계를 정보처리기사 실기 대비 핵심 내용으로 정리합니다.
포인터 산술 핵심 정리
| 개념 | 설명 | 예시 |
|---|---|---|
| 포인터 + 정수 | 포인터를 n칸 이동 | p + 1 |
| 포인터 - 정수 | 포인터를 n칸 뒤로 이동 | p - 1 |
*(p + n) | p에서 n칸 이동한 위치의 값 | *(p + 2) = p[2] |
| 배열 이름 | 첫 번째 요소의 주소 (포인터처럼 동작) | arr = &arr[0] |
포인터 산술이란? 쌩기초
포인터 산술(Pointer Arithmetic) 은 포인터에 정수를 더하거나 빼서 메모리 주소를 이동하는 연산입니다. 여기서 메모리 주소란 데이터가 저장된 위치를 가리키는 번호로, 포인터가 이 번호를 저장합니다.
포인터에 1을 더하면 다음 요소의 주소로 이동합니다. 이때 이동하는 바이트 수는 포인터가 가리키는 자료형의 크기에 따라 결정됩니다.
자료형에 따른 이동 크기 기초
포인터에 1을 더하면, 가리키는 자료형의 크기만큼 주소가 증가합니다.
| 자료형 | 크기 | p + 1의 이동량 |
|---|---|---|
char | 1바이트 | +1바이트 |
int | 4바이트 | +4바이트 |
double | 8바이트 | +8바이트 |
int 배열과 포인터 산술 기초
기본 이동
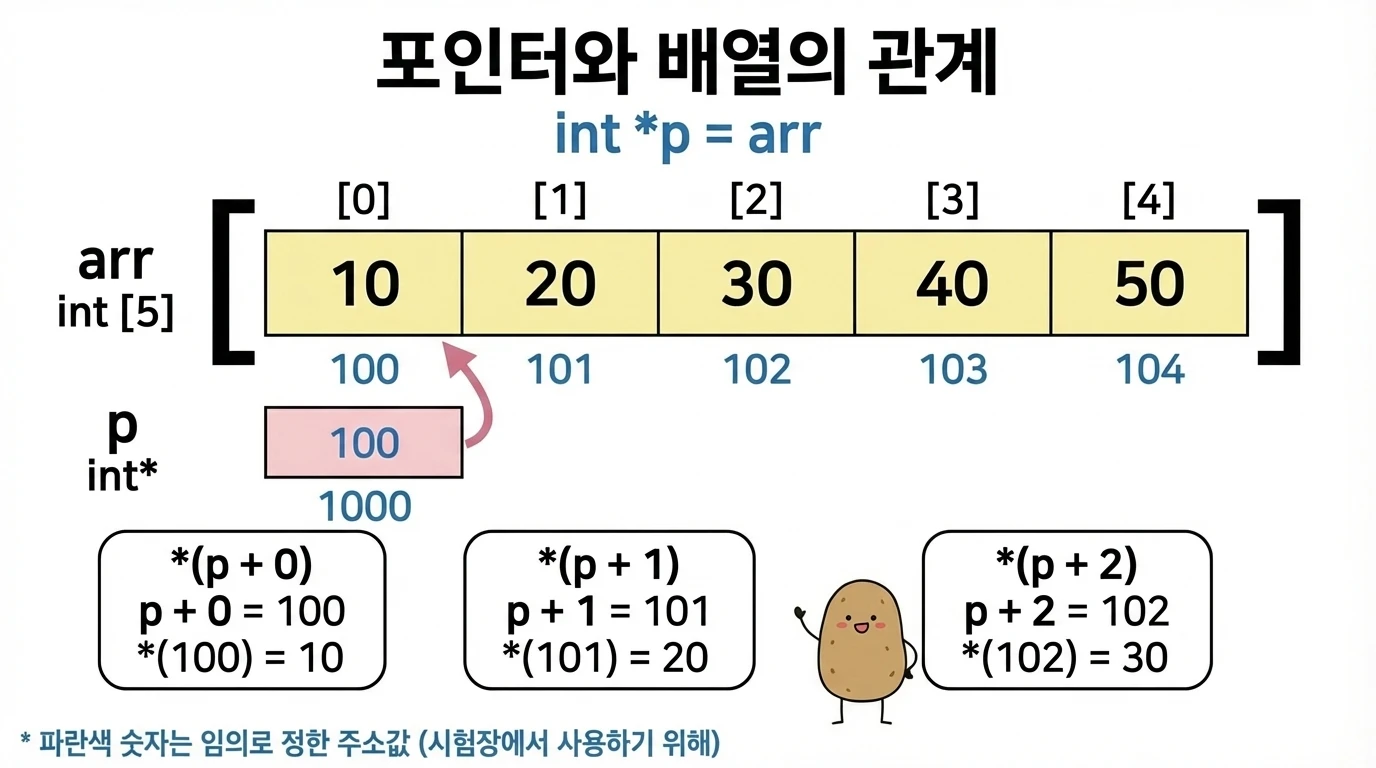
| 표현 | 동일한 표현 | 값 |
|---|---|---|
*p | p[0] = arr[0] | 10 |
*(p + 1) | p[1] = arr[1] | 20 |
*(p + 2) | p[2] = arr[2] | 30 |
시험 풀이에서는 실제 바이트 주소 대신 요소 하나당 주소를 1씩 증가시키는 임의 주소를 부여합니다. 자료형 크기는 무시하고, 칸 번호처럼 생각하면 됩니다. arr의 시작 주소를 100으로 놓으면:
p= 100 (arr[0]의 주소)p + 1= 101,*(p + 1)= 주소 101의 값 = 20p + 2= 102,*(p + 2)= 주소 102의 값 = 30
시작 위치가 다른 경우
포인터가 배열의 중간을 가리킬 수도 있습니다.
![포인터 산술 - p가 arr[2]를 가리킬 때 p-1, p, p+1](/_next/image?url=%2Fcoding%2Fc-language%2Fpointer-arithmetic%2Fint-array-offset.webp&w=1920&q=75&dpl=dpl_BY46TrDBHqwHpZFXXeiyVtxismUb)
| 표현 | 동일한 표현 | 값 |
|---|---|---|
*(p - 1) | arr[1] | 20 |
*p | arr[2] | 30 |
*(p + 1) | arr[3] | 40 |
임의 주소로 풀어보면, p = &arr[2] = 주소 102입니다.
p - 1= 102 - 1 = 101,*(p - 1)= 주소 101의 값 = 20*p= 주소 102의 값 = 30p + 1= 102 + 1 = 103,*(p + 1)= 주소 103의 값 = 40
배열 이름과 포인터 산술 기초
배열 이름은 첫 번째 요소의 주소입니다. 따라서 배열 이름에 직접 포인터 산술을 사용할 수 있습니다.
a[i]와 *(a + i)는 같다
C언어에서 배열 접근 a[i]는 내부적으로 *(a + i)로 변환됩니다. 이 두 표현은 완전히 동일합니다.
| 배열 표기법 | 포인터 표기법 | 의미 |
|---|---|---|
arr[0] | *(arr + 0) | 배열의 0번째 요소 |
arr[1] | *(arr + 1) | 배열의 1번째 요소 |
arr[i] | *(arr + i) | 배열의 i번째 요소 |
이 관계를 알면 시험에서 *(arr + 2)가 나왔을 때 arr[2]로 바꿔서 빠르게 풀 수 있습니다.
예를 들어, 위의 arr에 임의 주소를 부여하면:
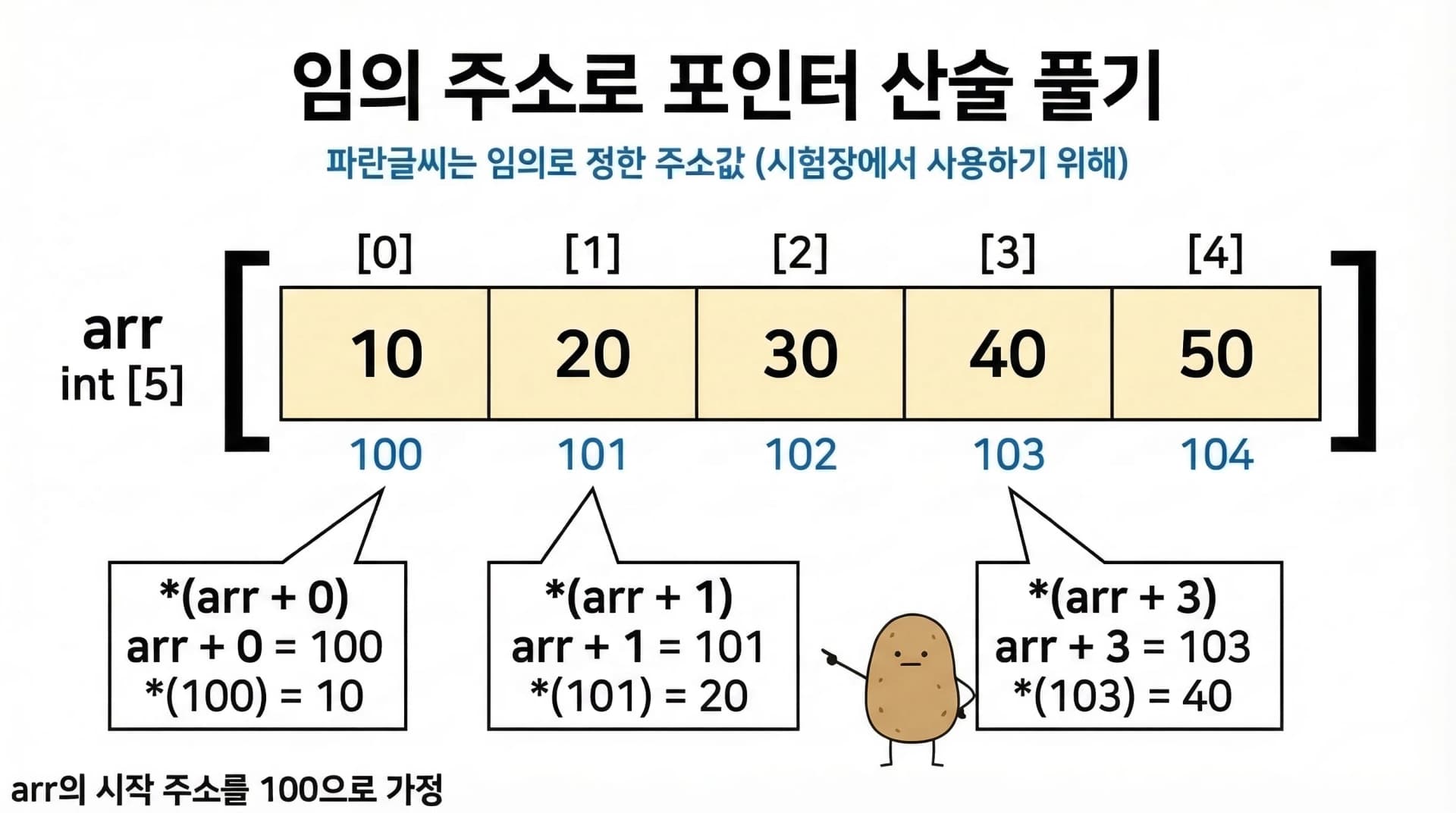
| 인덱스 | [0] | [1] | [2] | [3] | [4] |
|---|---|---|---|---|---|
| 값 | 10 | 20 | 30 | 40 | 50 |
| 주소 | 100 | 101 | 102 | 103 | 104 |
이제 포인터 산술을 주소로 풀 수 있습니다.
arr= 시작 주소 100arr + 0= 100,*(arr + 0)= 주소 100의 값 = 10arr + 1= 101,*(arr + 1)= 주소 101의 값 = 20arr + 3= 103,*(arr + 3)= 주소 103의 값 = 40
*arr도 마찬가지입니다. arr은 주소 100이므로 *arr = 주소 100의 값 = 10 (= arr[0]).
실제 기출문제 풀이에서 이 방식이 어떻게 활용되는지 확인해 보세요.
문자열 포인터 산술 기초
문자열은 char 배열이므로, 포인터 산술로 특정 위치부터의 부분 문자열에 접근할 수 있습니다.
문자열 리터럴과 포인터
문자열 리터럴 "KOREA"는 메모리에 저장된 char 배열의 시작 주소입니다.
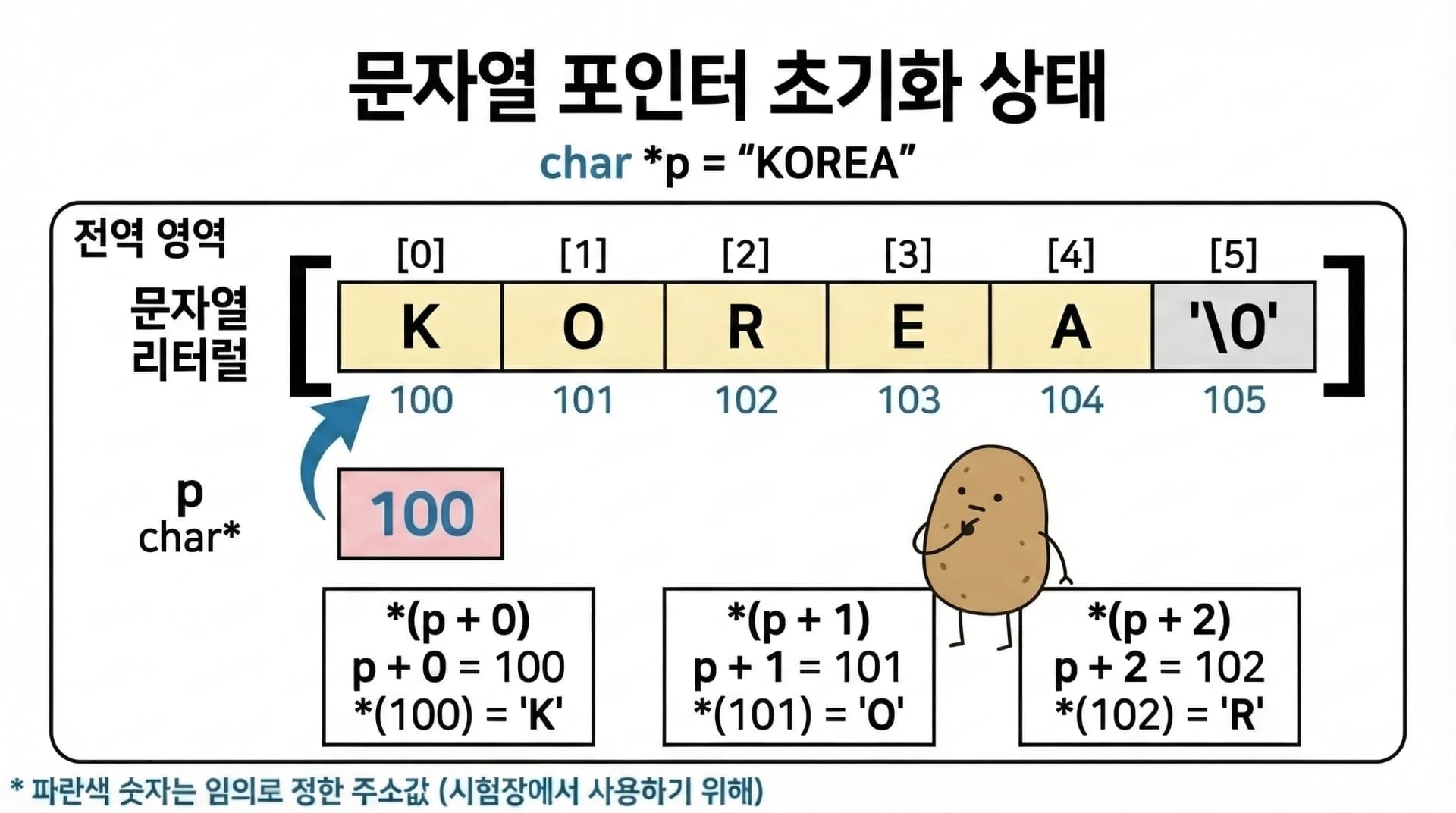
임의 주소를 부여하면, p는 주소 100 ('K'의 위치)입니다.
p + 0= 100,*(p + 0)= 주소 100의 값 ='K'p + 1= 101,*(p + 1)= 주소 101의 값 ='O'p + 2= 102,*(p + 2)= 주소 102의 값 ='R'
%s로 출력하면 해당 위치부터 끝까지
printf의 %s는 주어진 주소부터 널 문자('\0')까지 출력합니다. 포인터 산술로 시작 위치를 바꾸면 부분 문자열을 출력할 수 있습니다.
| 표현 | 시작 위치 | 출력 (%s) |
|---|---|---|
p | p[0] = 'K' | "KOREA" |
p + 1 | p[1] = 'O' | "OREA" |
p + 3 | p[3] = 'E' | "EA" |
%c로 출력하면 해당 위치의 한 문자
%s와 달리 %c는 한 문자만 출력합니다. 이때 *(p + n) 또는 p[n]으로 특정 위치의 문자를 가져옵니다.
*(p + n)과 *p + n의 차이 심화
괄호 위치에 따라 의미가 완전히 달라집니다. 먼저 결과가 확실히 다른 예시를 보겠습니다.
| 표현 | 해석 | 결과 |
|---|---|---|
*(p + 3) | p를 3칸 이동한 위치의 값 | 40 |
*p + 3 | p가 가리키는 값(10)에 3을 더함 | 13 |
*(p + 3)은 arr[3]의 값인 40이고, *p + 3은 arr[0]의 값 10에 3을 더한 13입니다. 괄호 하나로 결과가 완전히 달라집니다.
| 표현 | 연산 순서 | 의미 |
|---|---|---|
*(p + n) | 먼저 주소 이동, 그 다음 역참조 | p[n]의 값 |
*p + n | 먼저 역참조, 그 다음 정수 덧셈 | p[0]의 값 + n |
문자열에서도 같은 원리입니다. 컴퓨터는 문자를 숫자로 변환해서 저장하는데, 이 변환 규칙을 ASCII(아스키) 코드라고 합니다. 예를 들어 'A'는 65, 'B'는 66, ... 'E'는 69입니다.
이 경우는 우연히 결과가 같지만, 원리가 다릅니다. *(p + 4)는 5번째 문자를 읽은 것이고, *p + 4는 첫 번째 문자의 ASCII 값에 4를 더한 것입니다.
구조체 포인터 산술 심화
구조체 배열에서도 포인터 산술이 동일하게 적용됩니다. 구조체 포인터에 1을 더하면 다음 구조체 요소로 이동합니다.
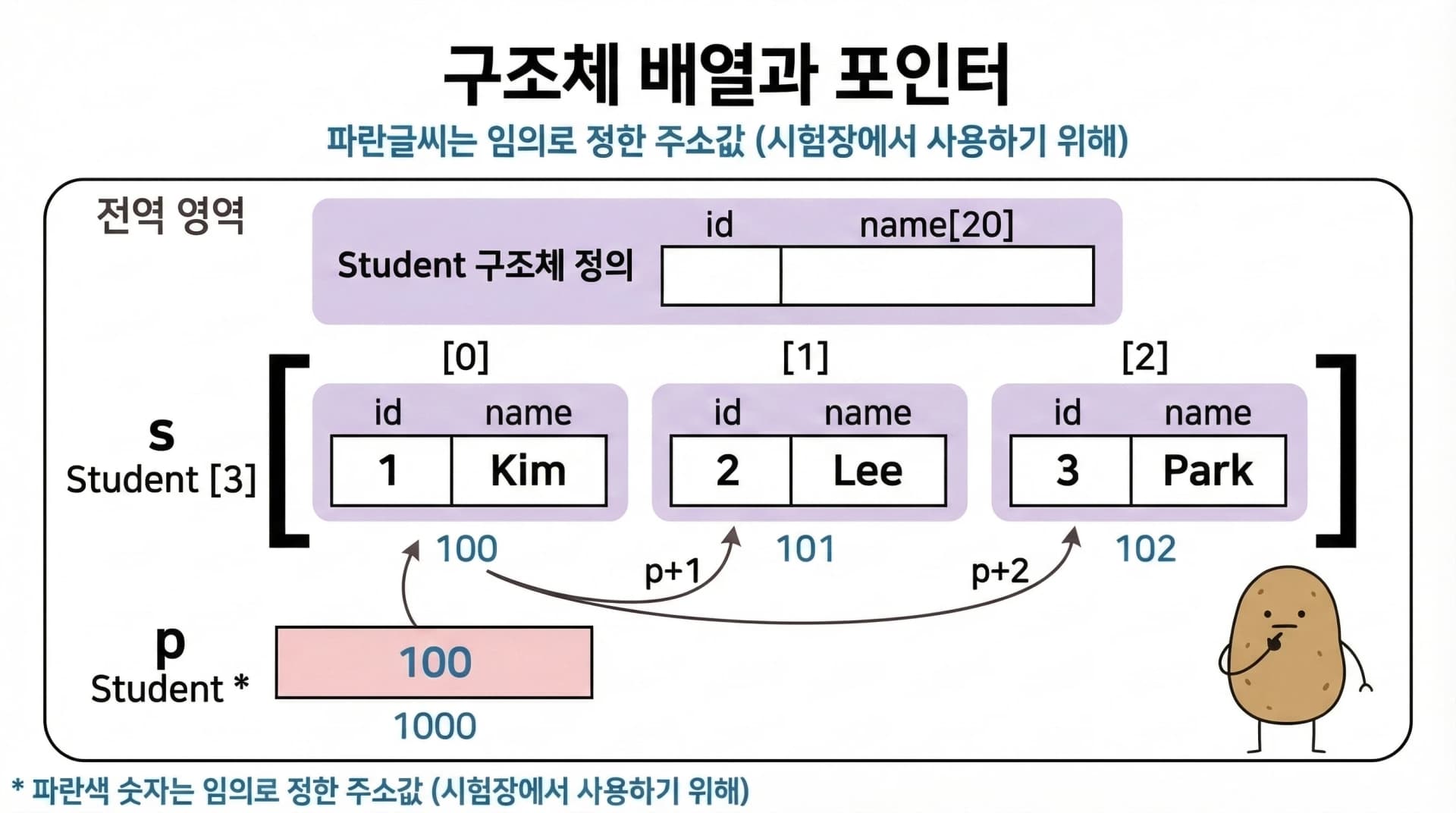
p->id는 "p가 가리키는 구조체의 id 멤버를 읽는다"는 뜻입니다. 점(.) 대신 화살표(->)를 쓰는 이유는 p가 구조체 자체가 아니라 구조체 포인터이기 때문입니다.
| 표현 | 동일한 표현 | 의미 |
|---|---|---|
p->id | s[0].id | 1 |
(p+1)->id | s[1].id | 2 |
(p+2)->name | s[2].name | "Park" |
임의 주소를 부여하면, p는 주소 100 (s[0]의 주소)입니다.
p= 100,p->id= 주소 100에 있는 구조체의id= 1p + 1= 101,(p+1)->id= 주소 101에 있는 구조체의id= 2p + 2= 102,(p+2)->name= 주소 102에 있는 구조체의name= "Park"
구조체 멤버가 문자열 포인터일 때
구조체 멤버가 char * 타입(문자열을 가리키는 포인터)이면, 해당 멤버에도 포인터 산술을 적용할 수 있습니다.
여기서 p->g는 "p가 가리키는 구조체의 멤버 g"를 뜻합니다. p가 test[1]을 가리키므로 p->g는 "DC"의 시작 주소이고, p->i는 2입니다.
p->g + 1은 문자열 "DC"의 시작 주소에서 1칸 이동한 것이므로, 두 번째 문자 'C'의 주소를 가리킵니다. %s로 출력하면 "C"가 출력됩니다.
여기서 p->g + 1이 (p->g) + 1로 해석되는 이유는 연산자 우선순위 때문입니다. -> 연산자는 +보다 우선순위가 높아서, 먼저 p->g로 멤버에 접근한 뒤 + 1로 포인터 산술이 적용됩니다.
포인터 증감 연산자 심화
p++와 p--도 포인터 산술입니다. 포인터를 한 칸씩 이동시킵니다.
*p++와 (*p)++의 차이
| 표현 | 해석 | 의미 |
|---|---|---|
*p++ | *(p++) | p가 가리키는 값을 읽고, p를 다음으로 이동 |
(*p)++ | p가 가리키는 값에 후위 증가 | p가 가리키는 값을 1 증가 |
++*p | ++(*p) | p가 가리키는 값을 1 증가 (전위) |
임의 주소를 부여해서 각각의 동작을 추적해 보겠습니다. arr의 시작 주소를 100으로 놓겠습니다.
int a = *p++; 실행 과정:
*p++는 *(p++)로 해석됩니다. 후위 ++이므로 현재 값을 먼저 사용하고, 그 다음에 p가 이동합니다.
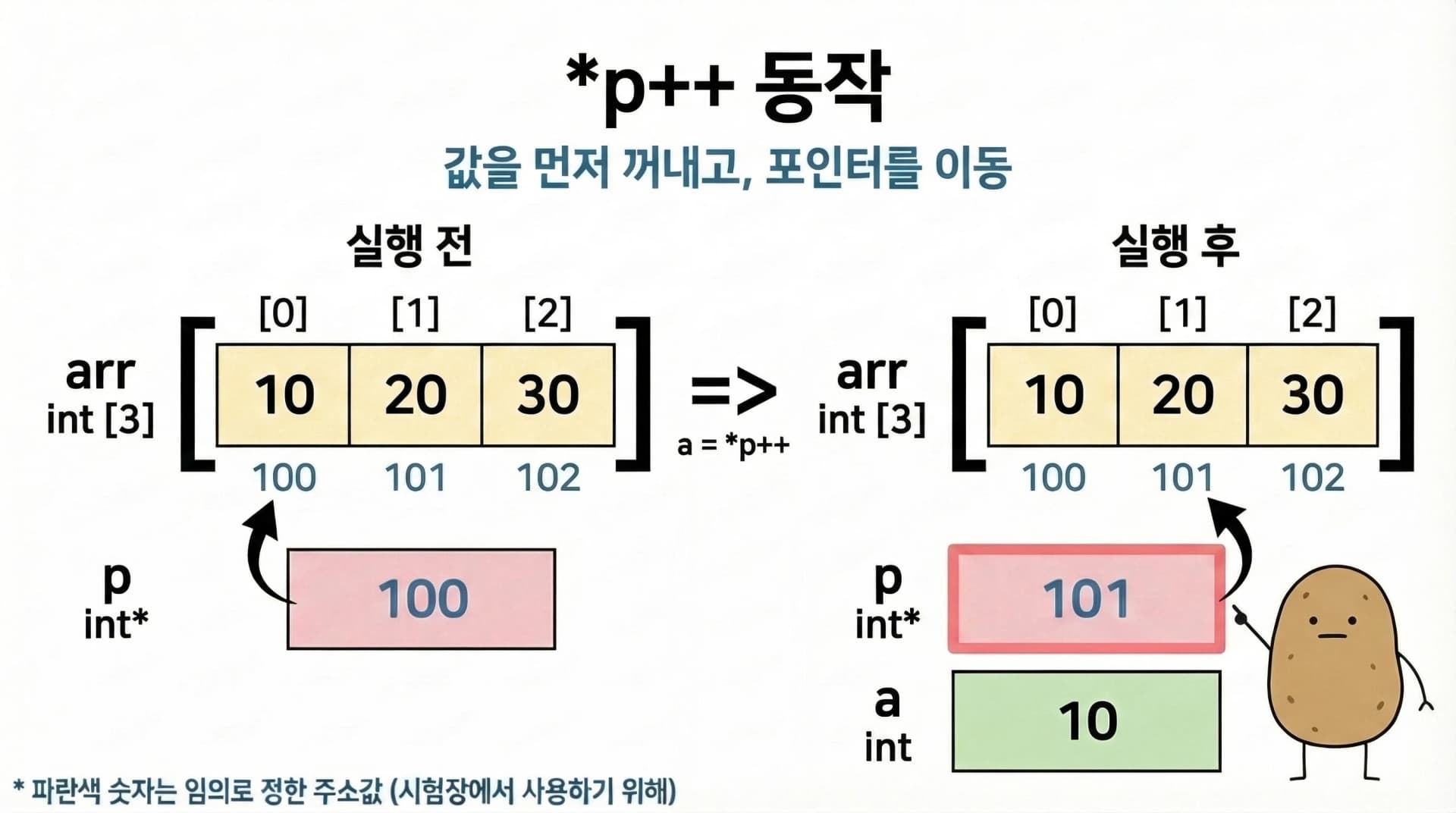
- 실행 전: p = 100 (arr[0]의 주소)
*p로 주소 100의 값 10을 읽어서a에 저장- 그 후
p++로 p가 101 (arr[1]의 주소)로 이동 - 결과: a = 10, p = 101
int b = (*p)++; 실행 과정:
(*p)++는 p가 가리키는 값에 후위 증가를 적용합니다. 포인터는 움직이지 않습니다.
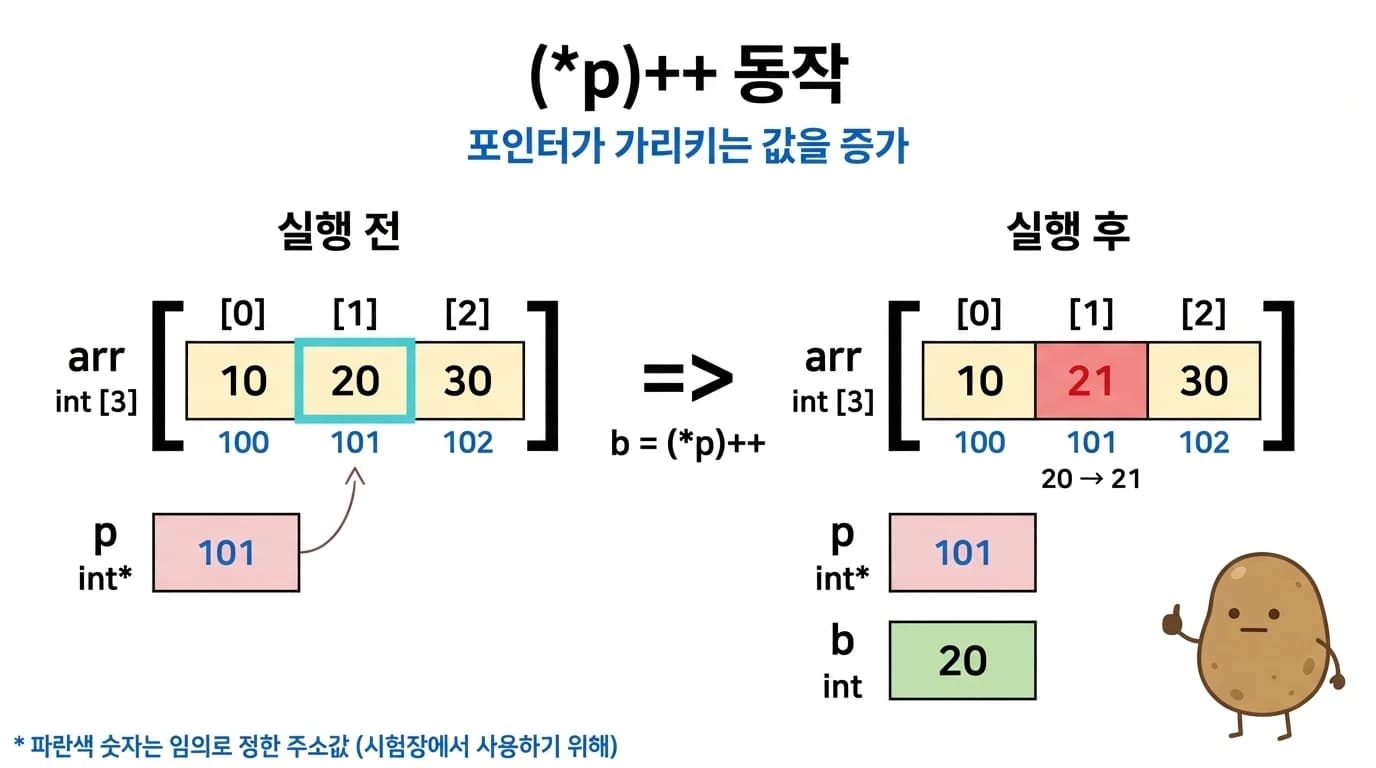
- 실행 전: p = 101 (arr[1]의 주소), arr[1] = 20
(*p)로 주소 101의 값 20을 읽어서b에 저장- 그 후
++로 arr[1]의 값이 20 → 21로 증가 - 결과: b = 20, arr[1] = 21, p는 여전히 101
핵심 차이는 ++가 무엇에 적용되는가입니다. *p++는 포인터(p)를 이동시키고, (*p)++는 포인터가 가리키는 값을 증가시킵니다.