문자열의 기초
선수학습(1개)
요약
문자열의 기본 개념을 알아봅니다. C언어의 char 배열과 널 문자, Java의 String 비교(== vs equals)와 String Pool 및 주요 메서드(charAt, substring, length 등), Python의 슬라이싱과 인덱싱 등 정보처리기사 실기에 자주 출제되는 문자열 핵심 개념을 정리합니다.
문자열 핵심 정리
| 개념 | 설명 | 예시 |
|---|---|---|
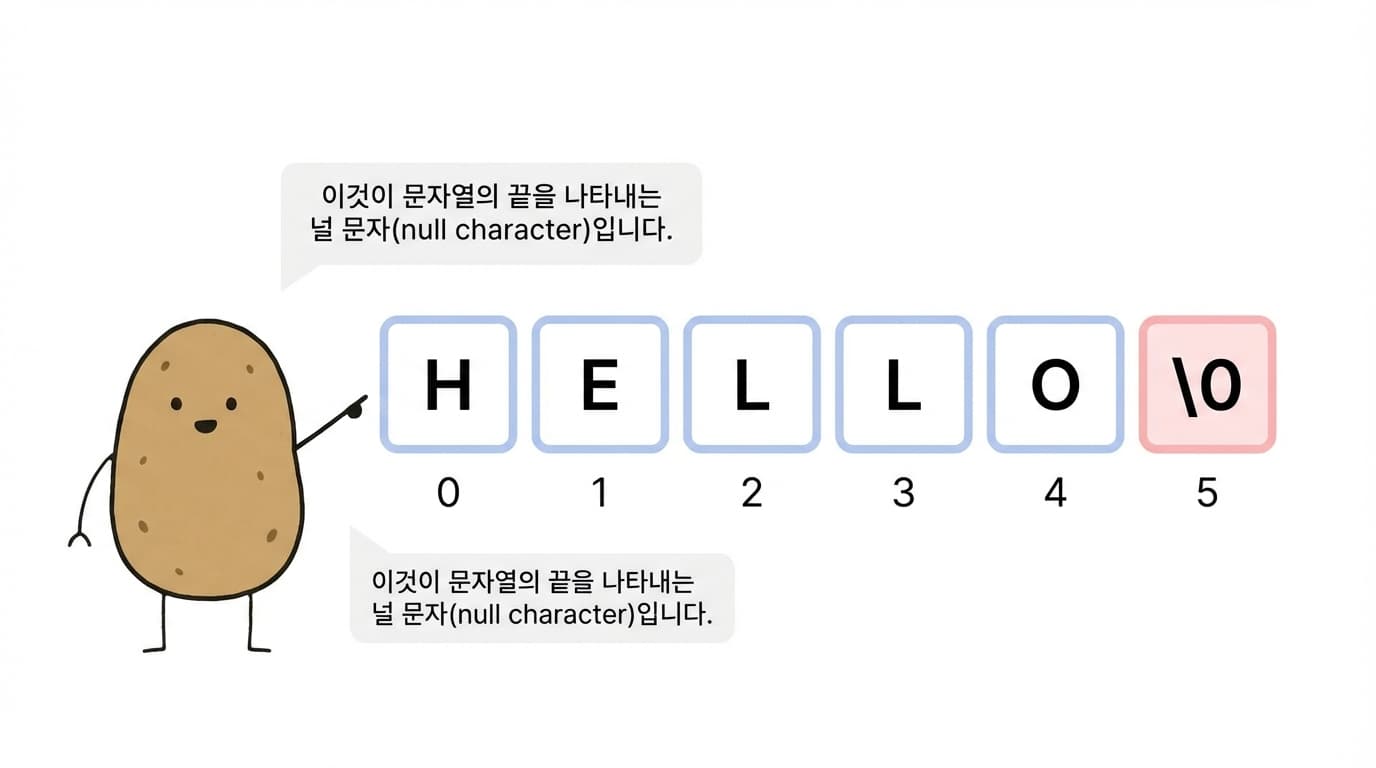
| 문자열 | 문자(char)들의 배열 | char str[] = "HELLO"; |
널 문자 ('\0') | 문자열의 끝을 표시하는 특수 문자 | str[5] == '\0' |
| 문자열 길이 | 널 문자를 제외한 문자 개수 | "HELLO" → 길이 5 |
문자열이란? 쌩기초
C언어에서 문자열(String) 은 문자(char)들의 배열입니다. 문자열의 끝에는 항상 널 문자 '\0' 가 자동으로 추가됩니다.
위 코드는 다음과 같이 메모리에 저장됩니다.
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 값 | 'H' | 'E' | 'L' | 'L' | 'O' | '\0' |
널 문자 ('\0') 쌩기초
널 문자 '\0' 는 문자열의 끝을 표시하는 특수 문자입니다. ASCII 코드 값은 0입니다.
C언어의 출력 함수들(printf, strlen 등)은 널 문자를 만날 때까지 문자를 처리합니다.
문자열 길이 계산 기초
문자열의 길이를 직접 계산하려면, 반복문으로 널 문자를 만날 때까지 문자를 세면 됩니다.
동작 과정
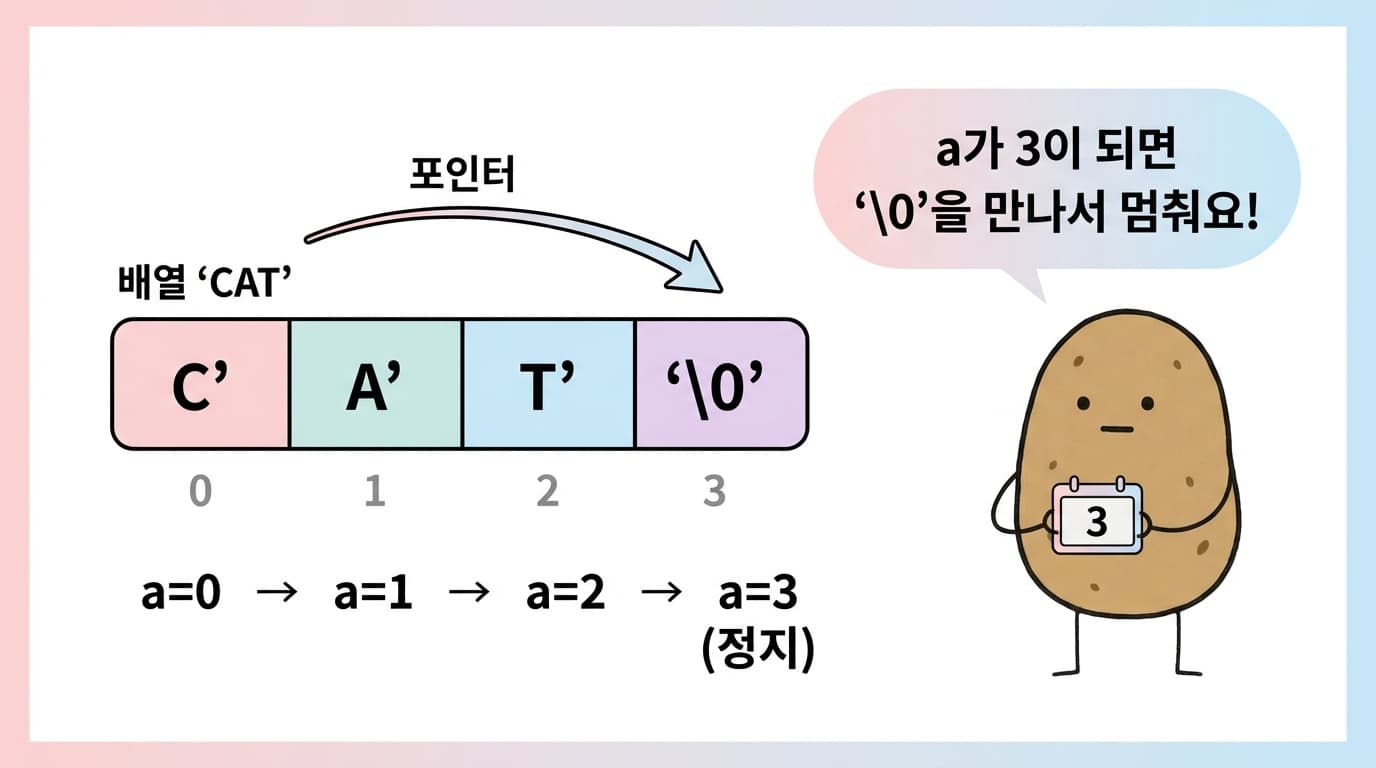
"REPUBLICOFKOREA"의 경우:
| 인덱스 | 0 | 1 | 2 | ... | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|
| 값 | 'R' | 'E' | 'P' | ... | 'E' | 'A' | '\0' |
a = 0:str[0]='R'(널 문자 아님) →a = 1a = 1:str[1]='E'(널 문자 아님) →a = 2- ... 반복 ...
a = 14:str[14]='A'(널 문자 아님) →a = 15a = 15:str[15]='\0'(널 문자!) → 루프 종료
루프 종료 후 a = 15이므로, 문자열 길이는 15입니다.
시험에서는 이렇게 구한 길이를 활용해 특정 위치의 문자를 묻는 문제가 자주 출제됩니다. 예를 들어 str[a - 2]는 str[13] = 'E'가 됩니다.
문자열 인덱싱 기초
문자열도 배열이므로 인덱스로 개별 문자에 접근할 수 있습니다.
뒤에서부터 접근하기
문자열 길이를 알면 뒤에서부터 문자에 접근할 수 있습니다.
| 접근 방식 | 인덱스 | 문자 |
|---|---|---|
| 마지막 문자 | str[len - 1] | 'O' |
| 뒤에서 두 번째 | str[len - 2] | 'L' |
| 뒤에서 세 번째 | str[len - 3] | 'L' |
문자열 처리 알고리즘 기초
문자열을 다루는 다양한 알고리즘이 시험에 출제됩니다. 포인터를 활용한 문자열 복사와 문자열 뒤집기가 대표적입니다. 문자열 포인터도 함께 학습하면 문자열 관련 문제를 더 쉽게 풀 수 있습니다.
문자열 핵심 정리
| 개념 | 설명 | 예시 |
|---|---|---|
| String 리터럴 | String Pool에 저장, 같은 값이면 같은 객체 공유 | "gamja" |
| new String() | Heap에 새로운 객체 생성, 값이 같아도 다른 객체 | new String("gamja") |
| == 연산자 | 두 변수가 같은 객체를 가리키는지 비교 (주소 비교) | str1 == str2 |
| equals() 메서드 | 두 문자열의 내용(값)이 같은지 비교 | str1.equals(str2) |
| String 메서드 | length, charAt, substring 등 문자열 조작 | str.length(), str.charAt(0) |
String Pool이란? 쌩기초
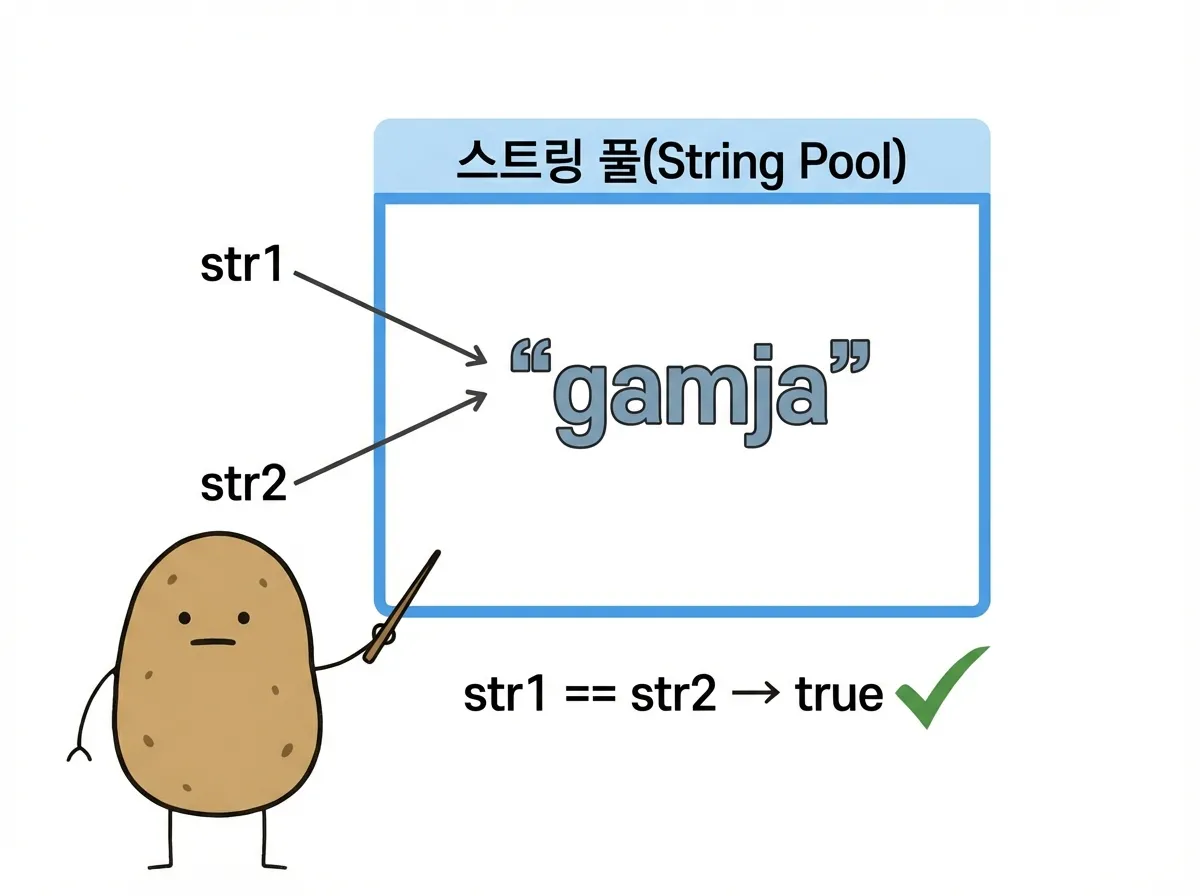
Java에서 String a = "gamja"라고 쓰면, "gamja"라는 데이터가 메모리에 만들어지고, 변수 a는 그 데이터가 있는 위치(주소)를 가리킵니다. 이처럼 메모리에 만들어진 데이터 덩어리를 객체, 객체의 위치를 가리키는 것을 참조라고 합니다.
Java는 문자열 리터럴(따옴표로 직접 작성한 문자열)을 String Pool 이라는 특별한 메모리 공간에 저장합니다. 같은 값의 리터럴이 여러 번 사용되면, 새로 만들지 않고 기존 객체를 재사용합니다.
str1과 str2는 String Pool의 같은 "gamja" 객체를 가리키므로 str1 == str2는 true입니다.
String 리터럴 vs new String() 기초
String 리터럴
따옴표로 직접 문자열을 작성하면 String Pool에 저장됩니다.
new String()
new 키워드를 사용하면 String Pool과 관계없이 Heap 메모리에 새로운 객체를 생성합니다.
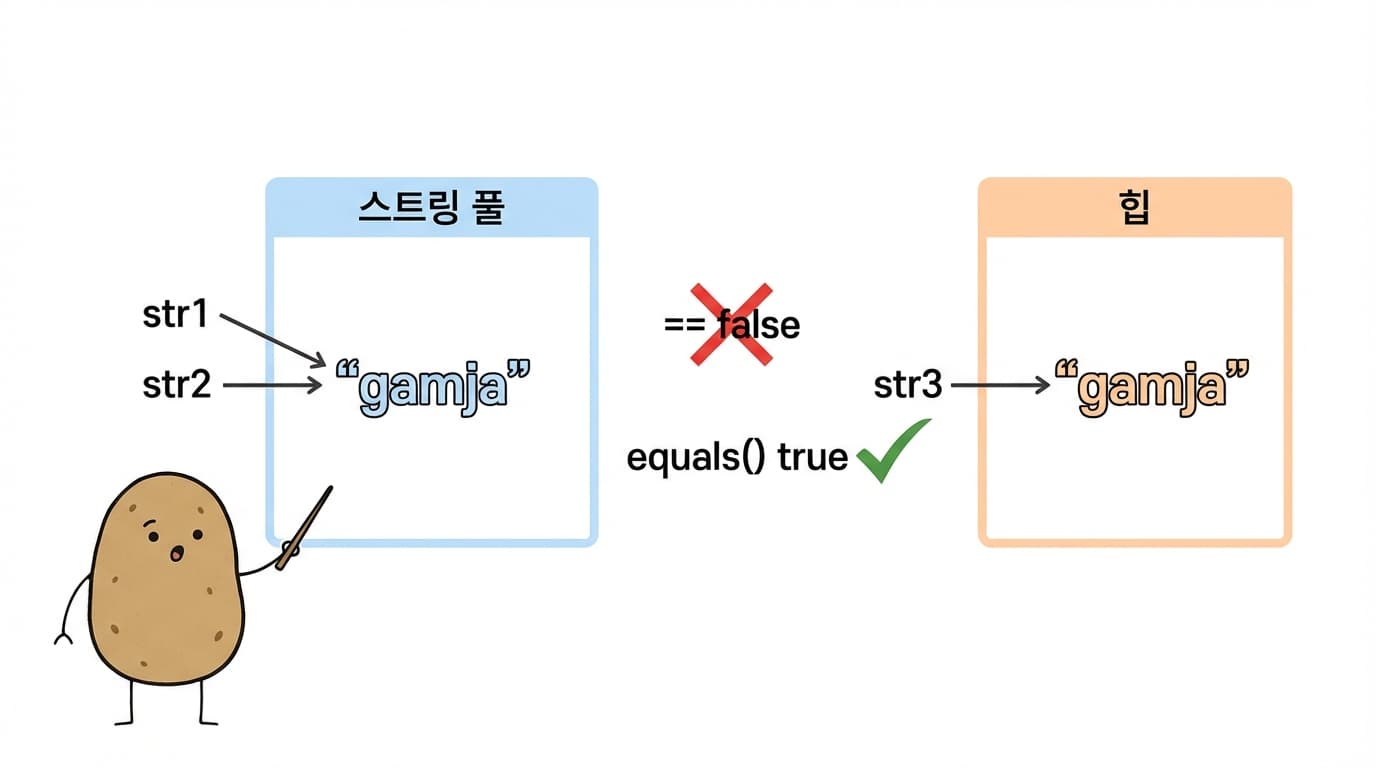
값은 "gamja"로 같지만, str1과 str3는 서로 다른 객체입니다.
메모리 구조
| 변수 | 생성 방식 | 저장 위치 | 주소 |
|---|---|---|---|
str1 | 리터럴 "gamja" | String Pool | 0x100 |
str2 | 리터럴 "gamja" | String Pool (재사용) | 0x100 |
str3 | new String("gamja") | Heap | 0x200 |
== 연산자와 equals() 메서드 기초
이제 문자열이 어떻게 저장되는지 알았으니, 비교 방법을 알아보겠습니다. Java에서 문자열을 비교하는 방법은 두 가지입니다.
위 예시에서는 둘 다 true이므로 차이가 보이지 않습니다. 둘 다 리터럴이기 때문에 String Pool의 같은 객체를 가리키기 때문입니다. 차이는 new String()을 사용할 때 드러납니다.
a는 String Pool에, c는 Heap에 저장되어 서로 다른 객체이므로 ==는 false입니다. 하지만 값은 같으므로 equals()는 true입니다.
| 비교 방식 | 비교 대상 | "gamja" vs "gamja" | "gamja" vs new String("gamja") |
|---|---|---|---|
== | 객체 주소 | true | false |
equals() | 문자열 값 | true | true |
equals() 메서드의 상세 사용법과 equalsIgnoreCase(), contains() 등 관련 메서드는 아래 String 메서드 섹션에서 다룹니다.
배열과 == 연산자 심화
== 연산자의 주소 비교는 문자열뿐 아니라 배열에도 동일하게 적용됩니다.
배열은 new로 생성하면 항상 Heap에 별도의 객체가 만들어집니다. 내용이 완전히 같아도 ==로 비교하면 false입니다.
배열의 내용을 비교하려면?
배열의 값을 비교하려면 Arrays.equals() 메서드를 사용합니다.
| 비교 대상 | 주소 비교 (==) | 값 비교 |
|---|---|---|
| String | str1 == str2 | str1.equals(str2) |
| 배열 | a == b | Arrays.equals(a, b) |
정리: == vs equals 한눈에 보기
| 구분 | == | equals() |
|---|---|---|
| 비교 대상 | 객체의 주소 (참조) | 객체의 값 (내용) |
| 리터럴끼리 | true (같은 Pool 객체) | true |
| 리터럴 vs new | false (다른 객체) | true |
| new vs new | false (다른 객체) | true |
| 배열끼리 | false (항상 다른 객체) | - (Arrays.equals() 사용) |
String 불변성과 StringBuilder
String은 불변(immutable) 객체이며, 반복 연결의 성능 함정을 가변 버퍼인 StringBuilder로 해결합니다. 자세한 내용은 String 불변성과 StringBuilder 페이지를 참고하세요.
String 메서드 기초
String은 문자열을 다루는 클래스입니다. String str = "Hello";처럼 문자열을 만들면 str.length(), str.charAt() 같은 메서드를 바로 쓸 수 있습니다.
length() — 글자 수
문자열의 글자 수를 돌려줍니다.
| 문자열 | length() 결과 |
|---|---|
| "Hello" | 5 |
| "AB" | 2 |
| "" | 0 |
charAt() — 특정 위치의 글자
문자열에서 원하는 위치의 글자 하나를 꺼냅니다. 위치는 0번부터 시작합니다. 결과는 char1 타입입니다.
| 인덱스 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 글자 | H | e | l | l | o |
substring() — 부분 문자열 추출
문자열의 일부분을 잘라서 새 문자열을 만듭니다.
substring(시작, 끝)에서 시작 위치는 포함하고 끝 위치는 포함하지 않습니다. 예를 들어 substring(1, 4)는 1번 글자부터 3번 글자까지만 추출합니다(4번은 미포함).
| 호출 | 범위 | 결과 |
|---|---|---|
"Hello".substring(1, 4) | 1번 ~ 3번 | "ell" |
"Hello".substring(0, 2) | 0번 ~ 1번 | "He" |
"Hello".substring(2) | 2번 ~ 끝 | "llo" |
toUpperCase() / toLowerCase() — 대소문자 변환
replace() — 글자 바꾸기
문자열에서 특정 글자(또는 문자열)를 다른 글자(또는 문자열)로 바꿉니다.
해당 글자가 여러 개 있으면 전부 바꿉니다.
split() — 문자열 쪼개기
구분자를 기준으로 문자열을 나눠서 배열(여러 값을 순서대로 묶어놓은 것)로 만듭니다.
indexOf() — 위치 찾기
문자열에서 특정 글자(또는 문자열)가 처음 나타나는 위치를 돌려줍니다. 찾지 못하면 -1을 돌려줍니다.
trim() — 앞뒤 공백 제거
문자열의 앞과 뒤에 있는 공백을 제거합니다. 중간에 있는 공백은 그대로 둡니다.
equalsIgnoreCase() — 대소문자 무시 비교
equals()와 같지만, 대소문자를 구분하지 않고 비교합니다.
contains() — 포함 여부 확인
문자열 안에 특정 문자열이 포함되어 있는지 확인합니다.
String 메서드 정리
| 메서드 | 하는 일 | 예시 | 결과 |
|---|---|---|---|
length() | 글자 수 | "Hello".length() | 5 |
charAt(n) | n번 글자 | "Hello".charAt(1) | 'e' |
substring(a, b) | a ~ b-1 추출 | "Hello".substring(1, 4) | "ell" |
toUpperCase() | 대문자로 | "hello".toUpperCase() | "HELLO" |
toLowerCase() | 소문자로 | "HELLO".toLowerCase() | "hello" |
replace(a, b) | a를 b로 교체 | "apple".replace('p', 'b') | "abble" |
split(구분자) | 쪼개기 | "A,B".split(",") | {"A", "B"} |
indexOf(x) | 위치 찾기 | "Hello".indexOf('l') | 2 |
trim() | 앞뒤 공백 제거 | " Hi ".trim() | "Hi" |
equals(s) | 내용 비교 | "abc".equals("abc") | true |
equalsIgnoreCase(s) | 대소문자 무시 비교 | "Hi".equalsIgnoreCase("hi") | true |
contains(s) | 포함 여부 | "Hello".contains("ell") | true |
문자열 핵심 정리
아래에서 하나씩 배울 내용을 미리 정리한 표입니다.
| 개념 | 설명 | 예시 | 결과 |
|---|---|---|---|
| 문자열 리터럴 | 홑/쌍/삼중 따옴표 모두 동일하게 str | 'hi' == "hi" | True |
| 인덱싱 | 특정 위치의 문자 한 개를 가져옴 | "PYTHON"[0] | P |
| 슬라이싱 | 부분 문자열을 잘라냄 (끝 인덱스 미포함) | "PYTHON"[1:4] | YTH |
| split() | 구분자 기준으로 문자열을 나눠 리스트로 반환 | "a b".split(' ') | ['a', 'b'] |
| join() | 구분자로 이터러블을 이어 붙여 문자열로 반환 | ' '.join(['a', 'b']) | 'a b' |
| strip()/replace()/find() | 양 끝 자르기·치환·인덱스 찾기 | " hi ".strip() | "hi" |
| input() | 사용자 입력을 문자열로 받음 | input() | (키보드 입력) |
| f-string | 중괄호 안에 변수를 직접 삽입 | f"{3+4}" | 7 |
| % 포맷팅 | 형식 지정자로 값을 삽입 | "%d점" % 100 | 100점 |
| 인접 문자열 자동 결합 | 리터럴 두 개가 나란히 있으면 자동 결합 | "abc" "def" | "abcdef" |
문자열 만들기 쌩기초
str은 string(문자열)의 약자입니다. 문자들을 따옴표로 감싸 묶은 자료형입니다.
따옴표는 큰따옴표("..."), 작은따옴표('...'), 삼중 따옴표("""...""" 또는 '''...''') 모두 사용할 수 있으며, 어느 것을 쓰든 완전히 동일하게 동작합니다.
C언어에서는 'a'는 문자(char), "a"는 문자열로 엄격히 구분되지만, Python에는 문자(char) 타입이 따로 없습니다. 홑따옴표든 쌍따옴표든 모두 str 하나입니다.
따옴표 중첩하기
문자열 안에 따옴표가 포함되어야 할 때는 바깥과 안쪽에 서로 다른 따옴표를 쓰면 이스케이프(\', \") 없이 간단히 작성할 수 있습니다.
숫자처럼 보여도 따옴표로 감싸면 str
출제된 바 있는 함정 포인트입니다. 따옴표로 감싸면 내용이 숫자여도 자료형은 str입니다.
문자열 인덱싱 쌩기초
Python 문자열의 각 문자에는 인덱스(위치 번호) 가 붙어 있습니다. 인덱스는 0부터 시작하며, 음수 인덱스로 뒤에서부터 접근할 수 있습니다.
| 양수 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 문자 | P | Y | T | H | O | N |
| 음수 인덱스 | -6 | -5 | -4 | -3 | -2 | -1 |
문자열 슬라이싱 기초
슬라이싱(Slicing) 은 문자열의 일부를 잘라내는 기능입니다. s[시작:끝] 형식을 사용하며, 끝 인덱스는 포함되지 않습니다.
step(간격) 지정
s[시작:끝:step] 형식으로 간격을 지정할 수 있습니다. step이 음수이면 역순으로 가져옵니다.
split() 메서드 기초
split(구분자)는 구분자를 기준으로 문자열을 분리해 리스트로 반환합니다.
리스트란 여러 값을 순서대로 담는 자료구조로, 배열과 비슷합니다.
join() 메서드 기초
'구분자'.join(이터러블[^1])은 리스트나 문자열 같은 이터러블의 요소들을 구분자로 이어 붙여 하나의 문자열로 만듭니다. split()은 문자열 → 리스트로 쪼개고, join()은 리스트 → 문자열로 합칩니다. 서로 정반대 작업입니다.
join()은 문자열의 메서드2입니다. 점(.) 앞에 구분자, 점 뒤에 join(...). 예를 들어 ','.join(리스트)에서 점 앞의 ','가 구분자입니다. 괄호 안에는 이어 붙일 값들의 묶음이 들어갑니다.
![' '.join(['hello', 'world']) 동작 과정: 리스트 요소 사이에 구분자가 끼어들어 하나의 문자열이 되는 흐름](/_next/image?url=%2Fcoding%2Fpython%2Fstring%2Fjoin-concat-flow.webp&w=3840&q=75&dpl=dpl_DYdGorXisq7NhZ8c3VUZieFidhfy)
split()과 join()은 한 쌍입니다
split()으로 문자열을 리스트로 쪼갠 뒤, join()으로 다시 붙이면 원본과 같은 문자열을 복원할 수 있습니다.
| 방향 | 메서드 | 입력 | 출력 |
|---|---|---|---|
| 쪼개기 | 문자열.split(구분자) | 문자열 | 리스트 |
| 합치기 | 구분자.join(이터러블) | 리스트/이터러블 | 문자열 |
여러 글자를 구분자로 써도 됩니다.
구분자를 교체할 때는 split() + join()을 한 번에 연결합니다.
제너레이터 표현식과 함께 쓰기
제너레이터 표현식은 (식 for 변수 in 반복 if 조건) 형태로 조건에 맞는 값만 하나씩 꺼내주는 표현식입니다. join()의 인자로는 리스트뿐 아니라 이터러블이면 무엇이든 넣을 수 있으므로, 제너레이터 표현식을 바로 넘겨 조건에 맞는 문자만 골라 합칠 수 있습니다.
c for c in y if c not in "lo"는y의 문자를 하나씩 꺼내,"lo"에 들어 있는 문자는 제외합니다.- 남은 문자들(
H,e)을''(빈 문자열)로 연결하므로 결과는"He"입니다.
기타 문자열 메서드 기초
split() 외에도 시험에서 자주 등장하는 문자열 메서드가 몇 가지 있습니다. 빈칸 채우기 문제에서 후보 메서드를 식별하려면 각 메서드가 무엇을 받아 무엇을 돌려주는지를 알아두어야 합니다.
| 메서드 | 동작 | 반환 자료형 | 예시 |
|---|---|---|---|
strip(문자) | 양 끝의 지정 문자(기본값은 공백)를 잘라냄 | 문자열 1개 | " hello ".strip() → "hello" |
replace(old, new) | 문자열 안의 old를 모두 new로 바꿈 | 문자열 1개 | "hello".replace("l", "L") → "heLLo" |
find(문자열) | 인자가 처음 등장하는 인덱스 | 정수 1개 | "hello".find("l") → 2 |
lower() | 모두 소문자로 | 문자열 1개 | "PYTHON".lower() → "python" |
upper() | 모두 대문자로 | 문자열 1개 | "python".upper() → "PYTHON" |
startswith(문자열) | 인자로 시작하는지 | True/False | "hello".startswith("he") → True |
split과 비교
다른 메서드는 결과로 문자열 1개나 정수 1개를 돌려주지만, split()만 리스트를 돌려줍니다. 다중 할당 (a, b = ...)으로 두 변수에 한 번에 받으려면 우변이 요소 2개짜리 리스트여야 하므로, 빈칸 자리에 들어갈 수 있는 메서드는 split()뿐입니다.
| 메서드 | 반환값 | 다중 할당 가능? |
|---|---|---|
split(' ') | 리스트 (요소 여러 개) | 가능 |
strip(' ') | 문자열 1개 | 불가능 |
replace(...) | 문자열 1개 | 불가능 |
find(' ') | 정수 1개 | 불가능 |
input() 함수 기초
input() 은 키보드로 입력한 값을 받아 문자열로 반환하는 내장 함수입니다. 반환값은 항상 문자열이므로, 숫자로 사용하려면 int(input())으로 변환해야 합니다.
f-string과 % 포맷팅 기초
문자열 안에 변수 값을 삽입하는 방법입니다.
f-string, % 포맷팅의 상세 사용법은 Python 출력 함수 페이지를 참고하세요.
인접 문자열 자동 결합
파이썬은 코드 안에서 문자열 리터럴 두 개가 공백만 사이에 두고 나란히 적혀 있으면 자동으로 한 문자열로 합칩니다. + 연산자를 쓰지 않아도 합쳐진다는 점이 핵심입니다.
같은 줄뿐 아니라 괄호 안에서 줄을 바꿔 가며 적어도 결합됩니다.
f-string끼리 또는 일반 문자열과 f-string끼리도 같은 규칙이 적용됩니다.