Python 기본 제공 함수 — range, len, type, sum, sorted, map, enumerate
요약
Python 기본 제공 함수 range, len, type, sum, sorted, enumerate, map, all, any를 한 페이지에 정리합니다. 각 함수의 기본 사용법, 예시 코드, 시험 주의 포인트까지 정보처리기사 실기에 필요한 내장 함수를 모아 다룹니다.
기본 제공 함수 핵심 정리
| 함수 | 설명 | 예시 |
|---|---|---|
range(끝) | 0부터 끝-1까지 정수(소수점 없는 숫자) 범위 생성 | range(5) → 0, 1, 2, 3, 4 |
len(x) | 요소 개수(길이) 반환 | len([1, 2, 3]) → 3 |
type(x) | 자료형 반환 | type(100) → <class 'int'> |
sum(x) | 숫자 요소의 합 반환 | sum([1, 2, 3]) → 6 |
enumerate(x) | 인덱스와 값을 동시에 반환 | enumerate(["a", "b"]) → (0, "a"), (1, "b") |
map(함수, x) | 각 요소에 함수를 적용한 결과 반환 | map(int, ["1", "2"]) → 1, 2 |
sorted(x) | 정렬된 새 리스트 반환 (원본 유지) | sorted([3,1,2]) → [1, 2, 3] |
all(x) | 모든 요소가 참이면 True | all([True, True]) → True |
any(x) | 하나라도 참이면 True | any([False, True]) → True |
range() — 정수 범위 생성 쌩기초
range()는 정수 범위를 생성하는 함수입니다. for문(같은 동작을 여러 번 반복하는 구문)과 함께 가장 많이 사용됩니다.
사용법 세 가지
기본 사용
for i in range(5):는 변수 i에 0, 1, 2, 3, 4를 차례로 넣으면서 아래 들여쓴 코드를 5번 반복 실행합니다. end=" "는 print()가 기본적으로 출력 후 줄을 바꾸는 것을 막고, 줄바꿈 대신 공백을 넣어서 옆으로 이어서 출력합니다.
range(5)는 for문이 반복할 때 0, 1, 2, 3, 4를 차례대로 하나씩 꺼내 쓸 수 있게 준비합니다. 5는 포함되지 않습니다.
시작과 끝 지정
간격 지정
range()와 C/Java 대응
C/Java를 배운 적이 있다면 참고하세요.
| range 표현 | 생성되는 값 | C/Java 대응 |
|---|---|---|
range(5) | 0, 1, 2, 3, 4 | for(i=0; i<5; i++) |
range(2, 6) | 2, 3, 4, 5 | for(i=2; i<6; i++) |
range(0, 10, 3) | 0, 3, 6, 9 | for(i=0; i<10; i+=3) |
역순 범위
간격에 음수를 넣으면 큰 수에서 작은 수로 내려갑니다.
range(5, 0, -1)은 5부터 시작해서 1씩 줄이며, 0 직전에서 멈춥니다. 0은 포함되지 않습니다.
list(range(...)) — 리스트로 변환
range()는 리스트와 달리 값을 메모리에 미리 모두 만들어 두지 않습니다. 시작·끝·간격 정보만 보관하고 있다가, 꺼내 달라고 할 때마다 계산해서 하나씩 넘겨주는 range 객체1를 돌려줍니다. 그래서 그대로 print()하면 값 목록 대신 range(0, 10) 처럼 범위 정보가 출력됩니다. 출력에 0이 포함된 이유는 생략한 시작값 기본값이 0이기 때문입니다.

list()로 감싸면 range가 계산을 모두 완료하여 값을 메모리에 담은 리스트를 만들어 줍니다.
리스트 변환이 필요한 경우:
print()로 값 목록을 확인할 때lst[2]처럼 인덱스로 특정 위치 값을 꺼낼 때 — range 객체도 인덱스 접근은 가능하지만, 리스트로 변환 후 사용하는 것이 일반적lst[1:4]처럼 슬라이싱으로 구간을 잘라낼 때 — range 객체도 슬라이싱은 되지만 결과가 다시 range 객체라, 잘라낸 값을 바로 다루려면 리스트로 변환.append(),.reverse()같은 리스트 전용 메서드를 쓸 때
인덱스는 리스트[위치번호] 형태로 특정 자리의 값을 꺼내는 방법입니다. lst[0]은 첫 번째 값, lst[-1]은 마지막 값입니다.
슬라이싱은 [시작:끝:간격] 형태로 구간을 잘라냅니다. lst[1:4]는 인덱스 1 ~ 3을 꺼내고, 간격을 주면 건너뛰며 꺼낼 수 있습니다.
lst[::-2]처럼 간격이 음수이면 뒤에서부터 앞 방향으로 간격만큼 건너뛰며 꺼냅니다. range()도 슬라이싱할 수 있지만 결과가 range 객체(range(0, 10, 2)[1:4] → range(2, 8, 2))라, 잘라낸 값을 리스트로 다루려면 list()로 변환합니다.
len() — 길이와 개수 쌩기초
len()은 여러 값을 담는 자료형의 요소 개수를 반환합니다. 문자열·리스트 같은 시퀀스2, 딕셔너리, 집합처럼 값을 여럿 담는 자료형을 통틀어 컬렉션이라고 부르고, 시퀀스는 그중 순서가 있는 한 종류입니다.
문자열에서의 len()
문자열의 len()은 문자 수를 셉니다. 공백, 점, 특수 기호도 한 글자로 셉니다.
range()와 함께 쓰기
len()은 리스트의 길이만큼 반복할 때 range()와 함께 자주 쓰입니다.
type() — 자료형 확인 기초
type(x)는 x가 어떤 자료형(데이터 타입)인지를 알려줍니다.
자료형 비교
type()의 반환값끼리 ==로 비교하면 같은 자료형인지 확인할 수 있습니다.
type(42)는 <class 'int'>이고, type(100)도 <class 'int'>입니다. 두 값이 같으므로 == 비교 결과는 True입니다.
조건문에서 자료형 판별
sum() — 합계 기초
sum(x)는 리스트나 튜플 같은 이터러블3에 들어 있는 숫자 요소의 합을 반환합니다. 문자열·리스트·튜플 같은 시퀀스도, 딕셔너리·집합도 모두 여러 값을 담는 컬렉션이라 이터러블에 속합니다.
평균 계산 패턴
sum()과 len()을 함께 사용하면 평균을 한 줄로 구할 수 있습니다.
제너레이터 표현식과 함께 쓰기
sum() 안에 제너레이터 표현식을 넣으면 조건에 맞는 값만 골라서 더할 수 있습니다.
%는 나머지 연산자입니다. x % 2 == 0은 "x를 2로 나눈 나머지가 0이다", 즉 짝수인지 확인하는 조건입니다. for x in nums if x % 2 == 0은 nums의 요소를 하나씩 꺼내 짝수인 것만 골라내고, sum()이 그 값들을 더합니다. nums에서 짝수는 2와 4이므로 결과는 6입니다.
enumerate() — 인덱스와 값 동시 반환 기초
enumerate()는 리스트를 for문으로 순회할 때 인덱스와 값을 동시에 돌려주는 함수입니다.
기본 사용법
enumerate(fruits)는 매 회차 (인덱스, 값) 형태의 튜플(소괄호로 묶은 값 묶음)을 만들고, i, v 두 변수가 그 튜플을 언패킹(묶음에서 값을 하나씩 꺼내 각 변수에 넣는 것)해서 받습니다. 변수를 두 개 쓰는 이유는 enumerate()가 인덱스와 값을 쌍으로 돌려주기 때문입니다.
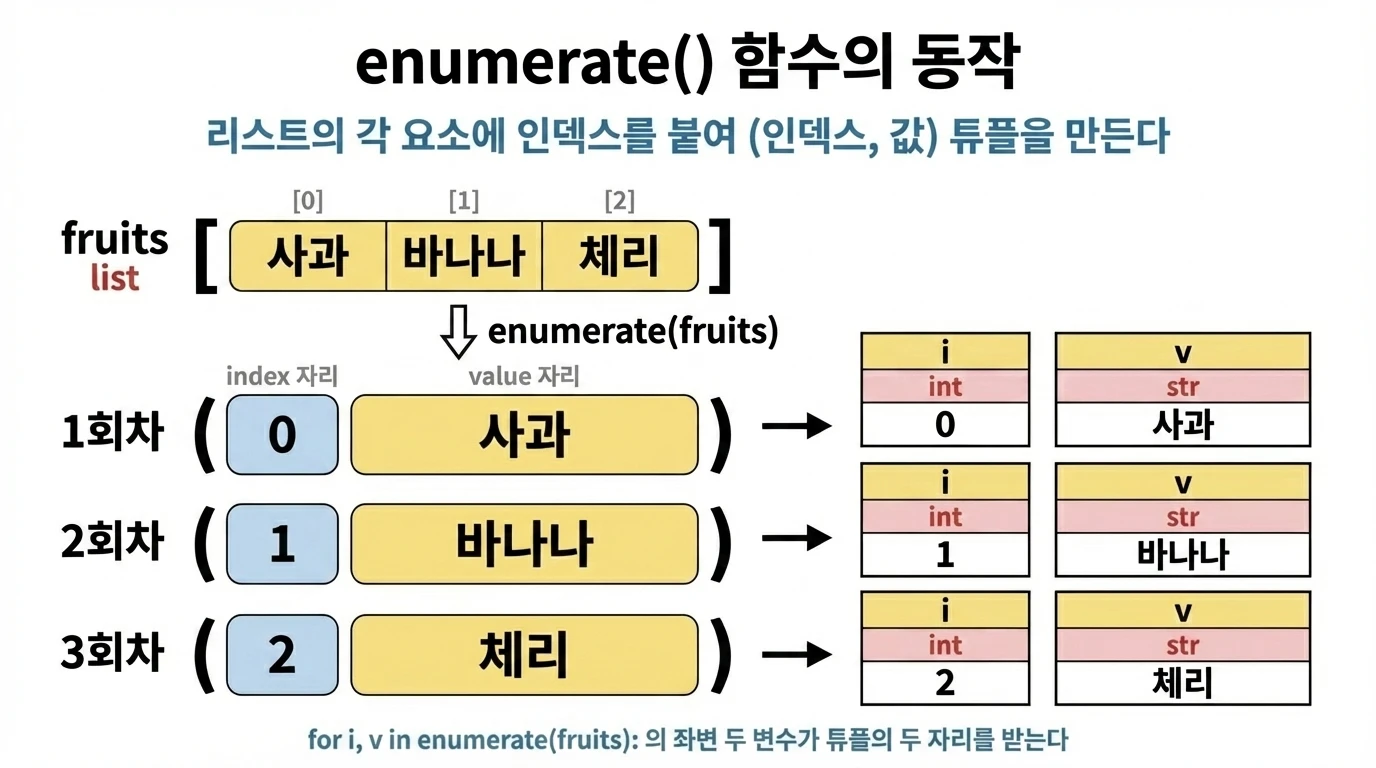
enumerate 없이 같은 동작 구현
range(len(fruits))로 인덱스를 만들고 fruits[i]로 값을 꺼내는 방식입니다. enumerate()를 쓰면 이 과정을 한 줄로 줄일 수 있습니다.
start 매개변수
기본 인덱스는 0부터 시작하지만, start 매개변수(함수에 넘겨주는 설정값)로 시작 번호를 바꿀 수 있습니다.
sorted() 함수 기초
sorted(이터러블)은 이터러블3의 요소를 정렬한 새 리스트를 반환합니다. 원본 데이터는 변경하지 않습니다.
리스트·집합·문자열 모두 사용 가능
sorted()는 어떤 이터러블에도 쓸 수 있으며, 항상 리스트를 반환합니다.
reverse 매개변수 — 내림차순
reverse=True를 넣으면 큰 값에서 작은 값 순으로 정렬합니다.
key=lambda — 정렬 기준 바꾸기
sorted()의 key 매개변수에는 함수를 넣습니다. 그 함수가 돌려주는 값을 기준으로 정렬이 수행됩니다. 한 번 쓰고 버릴 함수라면 람다 표현식을 바로 전달하는 것이 관례입니다.
람다의 일반 형태는 다음과 같습니다 — 이름 없는 함수를 한 줄로 만든 것입니다.
튜플 리스트를 두 번째 원소로 정렬
lambda x: x[1]은 "튜플 x가 들어오면 x[1]을 돌려주는 함수"입니다. sorted가 각 튜플마다 이 함수를 호출해 반환값(점수)으로 순서를 매깁니다.
문자열 길이로 정렬
딕셔너리를 값 기준으로 정렬 — items()와 결합
딕셔너리는 items()로 (키, 값) 튜플 묶음을 꺼낼 수 있습니다. 여기에 sorted(... key=lambda x: x[1])을 결합하면 값을 기준으로 정렬된 (키, 값) 리스트를 얻습니다.
빈도 카운팅(dict.get 패턴)으로 만든 딕셔너리를 값 기준으로 정렬하면 최빈값(가장 많이 등장한 값)을 바로 뽑을 수 있습니다.
| 데이터 형태 | 대표 패턴 | 결과 |
|---|---|---|
| 튜플 리스트 | sorted(data, key=lambda x: x[1]) | 두 번째 원소로 정렬 |
| 문자열 리스트 | sorted(words, key=lambda s: len(s)) | 길이로 정렬 |
| 딕셔너리 | sorted(d.items(), key=lambda x: x[1]) | 값 기준 정렬 |
map() — 함수를 각 요소에 적용 심화
map(함수, 이터러블)은 이터러블의 각 요소를 함수에 하나씩 넣어 호출하고, 그 결과를 하나씩 순서대로 꺼낼 수 있도록 저장해 둔 map 객체를 돌려줍니다. map 객체는 리스트와 달리 값을 미리 모두 만들어 두지 않고, 꺼낼 때마다 계산합니다. int는 정수 자료형이면서 동시에 값을 정수로 변환하는 함수로도 쓰입니다.
기본 사용법
위 코드에서 map(int, nums)는 nums의 각 요소("1", "2", "3")를 int() 함수에 넣어 int("1") → 1, int("2") → 2, int("3") → 3으로 변환합니다.
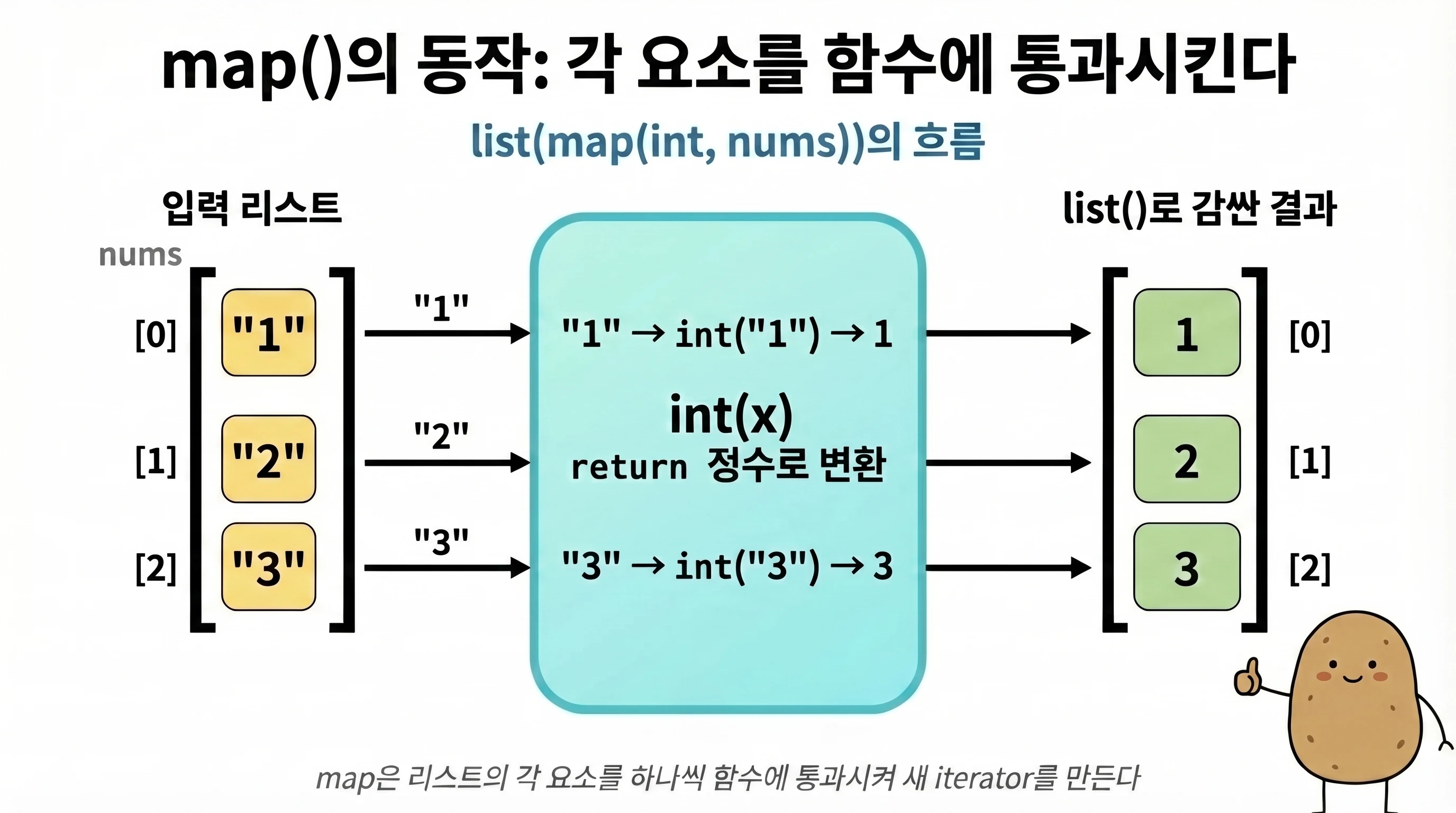
map 객체는 list()로 변환해야 합니다
map()은 리스트가 아니라 map 객체를 반환합니다. map 객체는 아직 계산이 완료된 리스트가 아니기 때문에, 그대로 print()하면 값 대신 <map object at 0x...> 처럼 Python 내부 메모리 위치가 출력됩니다.
map()의 동작을 for문으로 풀어 쓰기
lambda와 함께 쓰기
기본 제공 함수 대신 직접 만든 동작을 적용하려면 lambda 표현식(이름을 따로 짓지 않고 한 줄로 쓰는 간단한 함수)과 함께 씁니다.
lambda x: x + 100은 "x를 받아 x + 100을 돌려주는 이름 없는 함수"입니다. map()이 리스트의 각 요소를 이 함수에 넣어 결과를 모읍니다.
all()과 any() 심화
all()과 any()는 이터러블의 요소를 처음부터 끝까지 하나씩 확인한 뒤, 최종 결과를 True 또는 False 하나로 돌려주는 함수입니다.
all() — 모두 참이면 True
Python에서 숫자 0은 False로, 0이 아닌 숫자는 True로 취급합니다. 이 규칙이 all()과 any()에도 그대로 적용됩니다.
any() — 하나라도 참이면 True
all()과 any() 비교
| 함수 | 조건 | 빈 리스트일 때 |
|---|---|---|
all(x) | 모든 요소가 참이면 True | True |
any(x) | 하나라도 참이면 True | False |
제너레이터 표현식과 함께 쓰기
all()과 any() 안에 제너레이터 표현식을 넣으면 조건 판별을 한 줄로 작성할 수 있습니다.
x % 2 == 0 for x in nums는 nums의 각 요소에 대해 x % 2 == 0(짝수인지)을 검사합니다. 예를 들어 [2, 4, 6, 8]에서는 [2%2==0, 4%2==0, 6%2==0, 8%2==0] → [True, True, True, True]가 되고, all()이 이 결과를 받아 전부 True이므로 True를 반환합니다.